

DB2 verze 10.5
Společnost IBM vydala v červnu 2013 verzi DB2 10.5
Nová verze přinesla mnoho novinek, které zvyšují výkon, zlepšují bezpečnost, kompatibilitu a administraci. Mezi tou nejzásadnější jsou sloupcové tabulky BLU.
BLU
Funkcionalita BLU zcela mění způsob, jakým jsou data uložena a zpracovávána. To umožňuje rychle zpracovat velký objem dat v krátkém čase. Zrychlují se tak analytické dotazy, které vytváří Business Intelligence aplikace.
Sloupcové uložení
Tabulka je uložena po sloupcích. V tradičním uložení jsou na stránkách uloženy data po řádkách. V BLU uložení jsou data ve stránkách uložena po sloupcích. Lze tak eliminovat načítání zbytečných sloupců, nepotřebných pro vyhodnocení dotazu.
Jednoduchost
BLU se zapíná jednoduchým nastavením registrů. Maximum ladění se děje automaticky. Není potřeba indexů, MQT, MDC, range partition, statistický pohledů, hinty optimalizátorů, ... . Některé operace jsou zbytečné nebo se dělají automaticky - reorganizace, statistika, ...
Automatická komprese
Hledání vzorů se děje ve sloupcích a bývá efektivnější – sloupcová tabulka zabírá měně místa. Redukuje se tak I/O, více dat se vejde do paměti.
Přeskakování dat
Při vyhodnocování SQL se přeskakují data nepotřebná pro dotaz. K tomu se používá automatická Synopis tabulka.
Paralelní zpracování
Jedna stejná instrukce se zpracovává nad více daty (SIMD). Některé operace nevyžadují dekompresi dat (JOIN, =, >, <). Operátory zachovávají pořadí dat.
Maximální používání CPU
Dotaz je vždy rozložen na více jader. Některé operace vyžadují intra query paralelizaci (UPDATE, DELETE, INSERT, ALTER TABLE ADD UNIQUE KEY, RUNSTATS, LOAD). Efektivní plnění fronty CPU, aby se nejlépe používala cache
Optimální používání paměti
V paměti jsou nejpoužívanější data SQL dotazů. Není nutné mít všechna data v paměti. Mechanismus scan-friendly victim selection – vybírání stránek, které se uvolní z bufferpoolu jsou voleny podle složitějších kritérií. Dynamic list prefetch – nový přístup k datům používající synapis tabulku a page map index.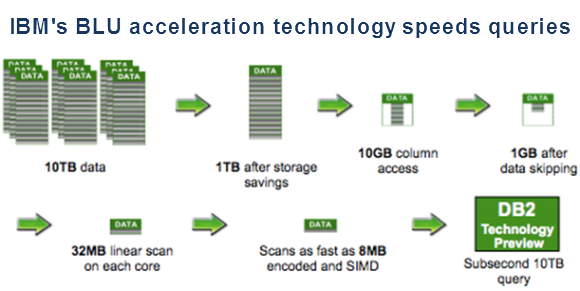
Indexy
Z indexů lze vynechat NULL hodnoty. U některých tabulek, to může značně zmenšit velikost indexů.
JSON
IBM již delší dobu označuje DB2 jako hybridní databázi. Neobsahuje jen relační část, ale i engine pro práci s hierarchickými XML dokumenty. Oba engine plyne spolupracují, takže lze v rámci SQL dotazu najednou dotazovat relační data, ale i části XML dokumentů. Totéž platí pro dotazovací jazyk XQUERY.
V této verzi je přidán engine pro práci se sloupcovými daty a i engine pro práci s JSON dokumenty.
Ve stejné databázi lze vedle relačních a XML dat uložit i JSON dokumenty. K jejich dotazování slouží MongoDB API nebo JSON API.
JSON dokumenty mohou být i indexovány.
Limity
Byly zvýšeny limity edicí.
- Express-C: 2 CPU, 16 GB RAM
- Express: 4 CPU, 64 GB RAM
- Workgroup:16 CPU, 128 GB RAM
- Advanced Workgroup:16 CPU, 128 GB RAM


